


Analyze with AI
Get AI-powered insights from this Mad Devs article:
Reliability is crucial for systems and products, and understanding metrics like MTBF, MTTR, MTTA, and MTTF is key. In this article, we will explore these metrics' definitions, calculations, and applications.
So, you can discover how MTBF measures reliability and factors influencing failure rates. Explore MTTR and strategies to minimize downtime. Moreover, learn about MTTA and effective incident response techniques. Finally, you will uncover MTTF and its role in product lifespan estimation.
We will consider real-world examples, and best practices are provided throughout. So, you will equip yourself with the knowledge to assess reliability, optimize performance, and make data-driven decisions. Join us as we unravel the mysteries behind these metrics, empowering your organization with insights for operational excellence.

Understanding the mean time between failures
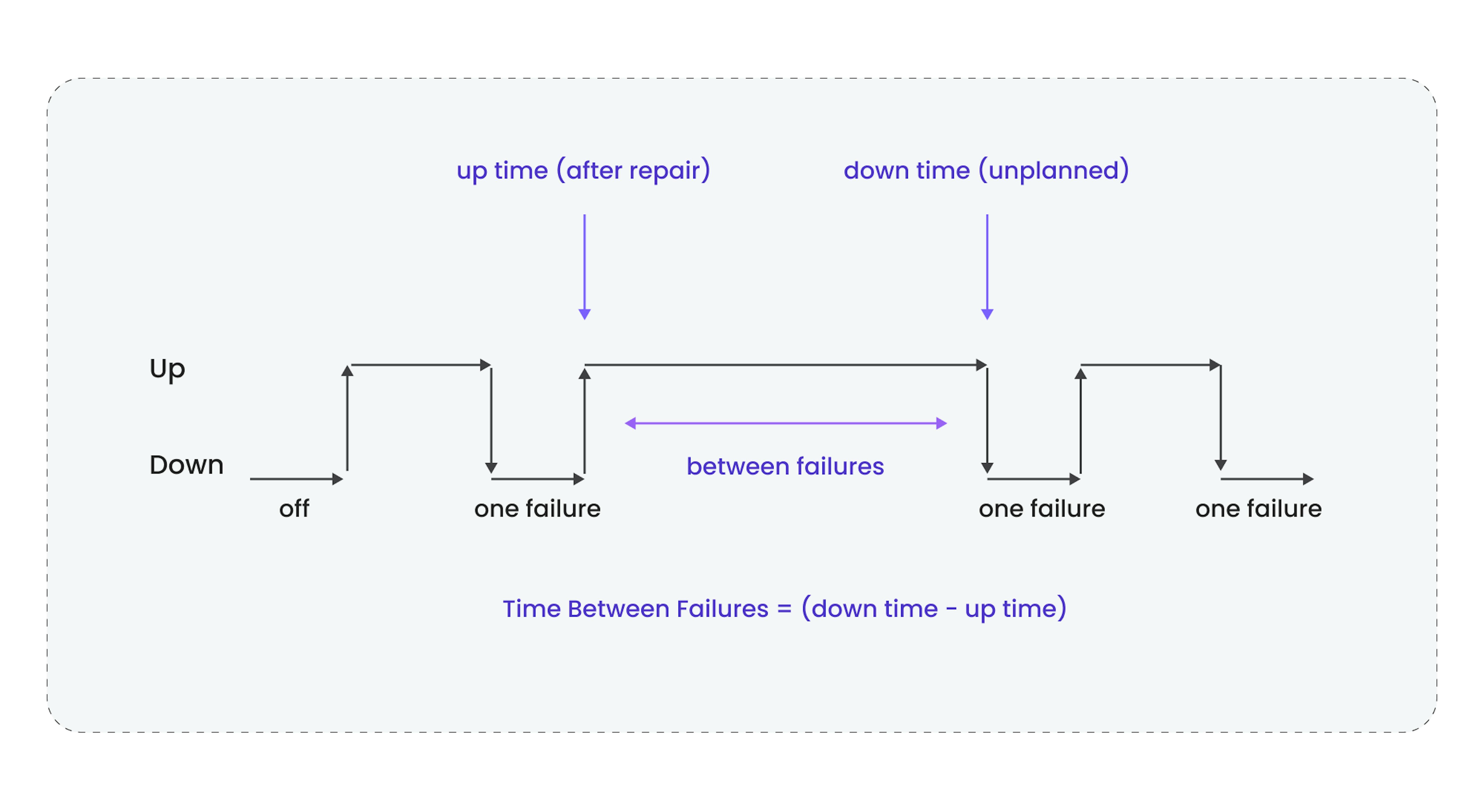
Mean time between failures, or MTBF, measures the average time between failures in a system. Knowing your MTBF provides valuable insights into the reliability and performance of equipment, components, or entire systems.
- A higher MTBF indicates a longer average time between failures, implying greater reliability and stability.
- On the other hand, a lower MTBF suggests a higher frequency of failures and a less reliable system.
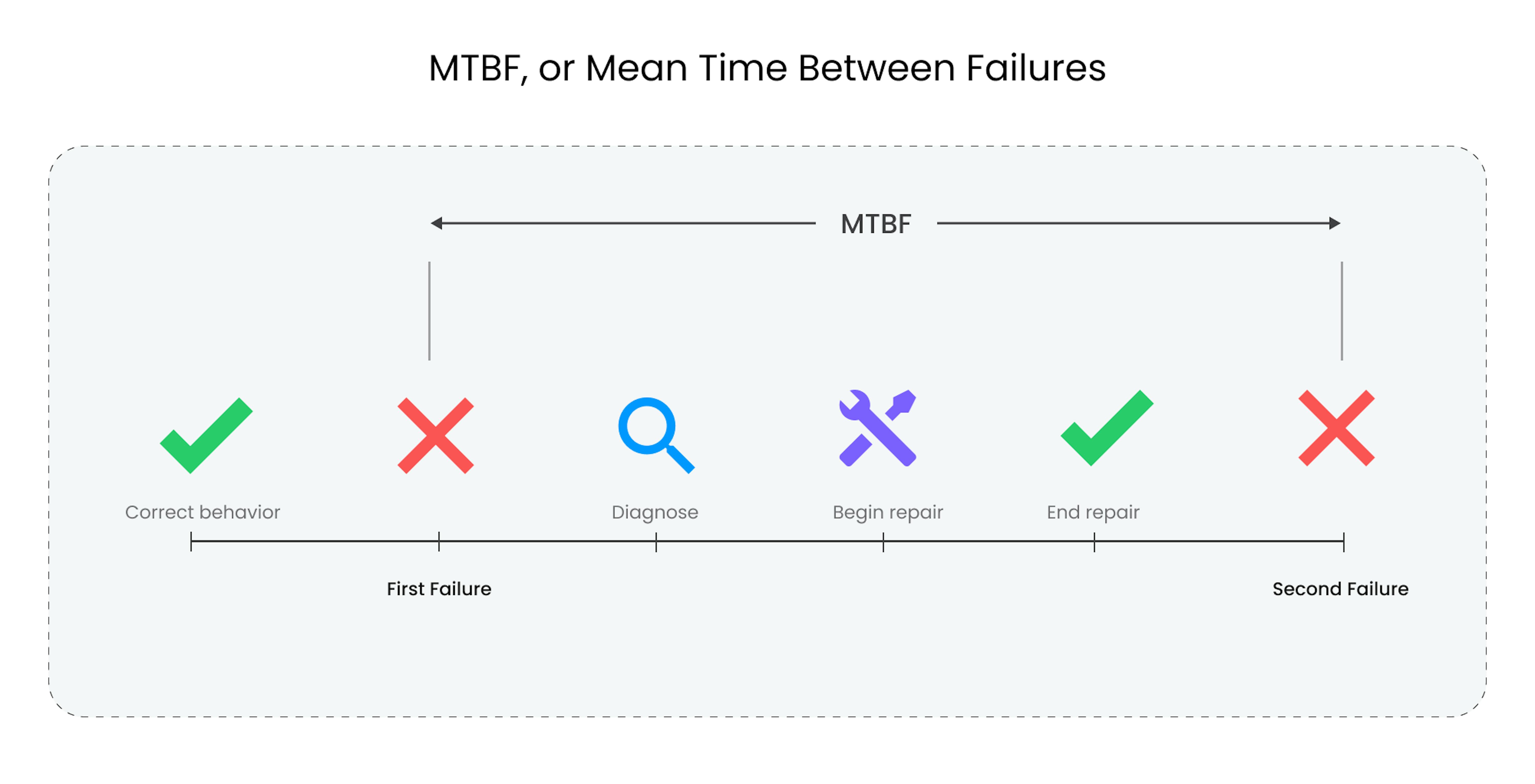
Reliability analysis utilizes MTBF to predict the expected reliability of a system over a specific period. By assessing it, organizations can identify potential areas of improvement, develop maintenance strategies, and allocate resources effectively.
MTBF is particularly significant in critical systems, where a failure can result in severe consequences such as production downtime, financial losses, or compromised safety. By monitoring and optimizing it, organizations can reduce the frequency of failures, minimize downtime, enhance operational efficiency, and improve customer satisfaction.
MTBF calculation
Calculating involves various methods and considerations.
MTBF is calculated using the following formula:

Total Operational Time / Total Number of Breakdowns = MTBF (hrs.)
Total operational time refers to the period of time during which your equipment runs without any breakdowns. Operating hours are typically used to measure this. Both planned maintenance tasks and unplanned repairs are included.
Total breakdowns refer to the instances when the equipment experiences failure during operation, encompassing various types of failures such as mechanical, electrical, software, or human errors.
The implications of the results are as follows:
- A higher MTBF signifies a lower occurrence of equipment problems throughout its lifespan, resulting in reduced repair costs and unplanned downtime.
- A lower MTBF indicates a higher likelihood of frequent failures, necessitating proactive planning and the implementation of suitable asset management strategies.
The objective is to achieve a high average time between failures, reflecting the equipment's good health. The specific ideal value varies depending on factors such as the asset type, usage scenario, operating environment, and maintenance program in effect.
Factors that influence MTBF
Several factors can influence MTBF, including:
- Component quality. The quality of components used in a system significantly impacts its reliability. Higher-quality components tend to have longer MTBF values.
- Environmental factors. The operating environment, including temperature, humidity, vibration, and other external conditions, can affect MTBF.
- Maintenance practices. Regular maintenance, including preventive maintenance, can improve MTBF by identifying and addressing potential failure points before they occur.
- Operating conditions. Factors like load, stress, and usage patterns can influence MTBF. Systems operating under heavy loads or stressful conditions may experience shorter MTBF.
- Design and manufacturing. The design and manufacturing quality of a system impact its reliability. Well-designed and manufactured systems tend to have higher MTBF values.
By considering these factors and implementing strategies to address them, organizations can work towards improving MTBF and enhancing the reliability and longevity of their equipment.
Challenges in capturing MTBF
Capturing MTBF is challenging due to the need for accurate data from multiple sources. Collaboration across the organization, especially with maintenance teams, is vital. Teams must be well-trained and equipped to ensure data accuracy. Effective analysis is key to identifying trends. Calculating MTBF requires accounting for variances that may affect data quality and validity. Some specific challenges include:
- Variances in data collection. MTBF rates can vary depending on the measured equipment and operating environment.
- Poor data tracking. To accurately measure effectiveness and identify areas for improvement, all breakdown incidents, including human errors, must be diligently tracked and recorded.
- Incomplete maintenance records. Without comprehensive tracking of historical data, it is challenging to determine the performance and issues related to specific equipment parts.
- Varying definitions of "failure". Different organizations have different interpretations of what constitutes a failure, such as lost production or anything less than 100% uptime. Consistent definitions are crucial for accurate MTBF calculations.
To calculate the actual value of an asset, it is essential to consider all events that affect its availability, regardless of their categorization by manufacturers. Overcoming these challenges requires robust data tracking systems, comprehensive maintenance records, and alignment on failure definitions across the organization.
Examples illustrating the application of MTBF
- World of electronics. MTBF is used to estimate the reliability of various components, such as voltage regulators and power supplies.
- Manufacturing. MTBF is often used to measure the reliability of production equipment. This data helps manufacturers plan maintenance and equipment replacements, thereby boosting reliability, minimizing downtime, enhancing efficiency, and increasing profits.
- Network and communication systems. SD-WAN technology is often implemented to increase reliability and reduce downtime.
- Medical field. MTBF can be used to measure the reliability of medical equipment and devices, such as MRI machines. Knowing the MTBF of the equipment can help hospitals plan for maintenance and repairs.
- Aerospace industry. MTBF is used to measure the reliability of avionics systems, such as flight control systems and communication systems. Knowing the MTBF of these systems helps ensure their safe and reliable operation.

Exploring MTTR
MTTR stands for mean time to repair, mean time to recover, mean time to resolve, mean time to resolve, mean time to restore or mean time to reply.
Disclaimer: The truth is that MTTR represents four different measurements, not one metric with one meaning. R can stand for repair, recovery, response, or resolve, and each of these metrics has its own nuance and meaning. First, you should clarify which MTTR your team is talking about and how they define it if they're talking about tracking it so everyone is aware of what exactly you're tracking and what they mean.
It refers to the average time it takes to troubleshoot and resolve a problem. When a system fails, the mean time to repair (and restore) it is the average amount of time it takes to fix it.
Mean time to repair refers to the average amount of time it takes to repair a component or system.
Thus, MTTR provides insight into an organization's ability to maintain its systems, equipment, applications, and infrastructure and repair such equipment in the event of an outage.
Once a fault has been discovered, MTTR includes:
- Diagnostic,
- Repair,
- Testing,
- Other actions until the service is returned to end users.
MTTR measures how quickly a component or service can be repaired, indicating the potential impact on business operations. A shorter MTTR implies that tech issues related to the component can be resolved quickly, minimizing their impact on the business. Conversely, a higher MTTR suggests that a component failure could result in a significant service outage, affecting the business more severely.
MTTR serves as a valuable indicator of the financial consequences of a tech disaster, as it measures the duration of downtime for critical systems. A higher MTTR for an IT team increases the risk of business disruptions, customer dissatisfaction, and revenue loss when tech problems arise.
Technology failures are inevitable, and understanding the MTTR allows businesses to gauge their ability to respond swiftly and efficiently to breakdowns and restore normal operations. Lower MTTR rates generally reflect a robust computing environment and a well-performing tech function.
How to calculate MTTR?
MTTR= total repair time / total number of repairs
In order to calculate MTTR, you must first determine how long it takes to repair an asset.
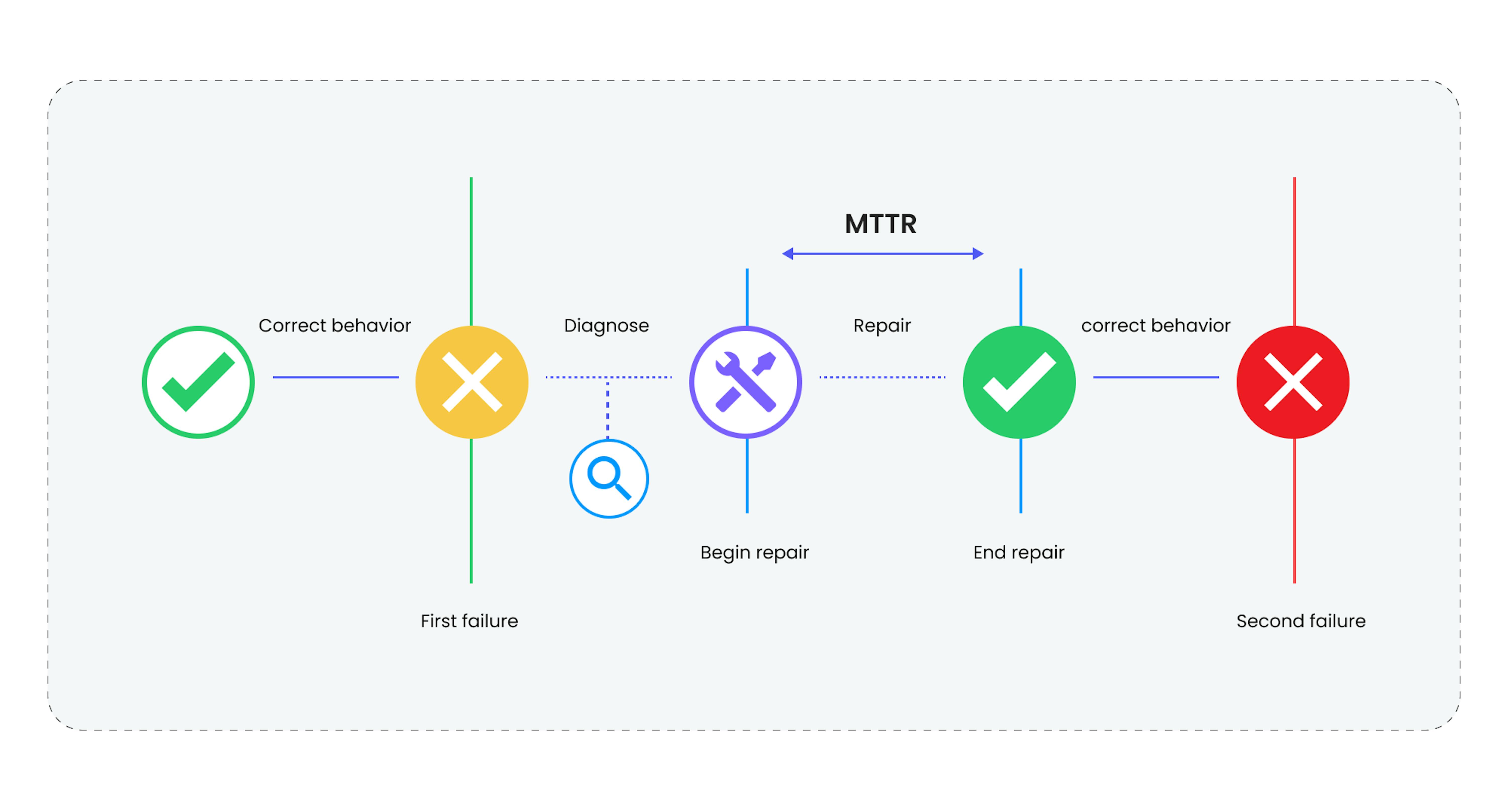
Let's assume you have a press machine with a challenging motor. During the course of a week, you spent a total of four hours working on it. The first repair session took an hour and a half, while the second repair session required two and a half hours. Although the repair times were relatively similar in this case, it's important to note that repair times can vary significantly. Despite these variations, you can still utilize MTTR (Mean Time to Repair) as a metric.
Now, let's consider another asset where the first repair took thirty minutes, the second repair took three hours, and it is now the third time it requires attention after two days. To calculate MTTR, you divide the total downtime caused by failures by the total number of failures. For example, if the system experienced three failures within a month, resulting in a total of six hours of downtime, the MTTR would be two hours.
What factors influence MTTR?
Several factors can influence the MTTR of a system or asset, such as:
- The complexity of the issue or problem can greatly impact the time required for repair. More complex issues may involve intricate troubleshooting and diagnosis processes, leading to longer repair times.
- The availability of necessary resources, such as spare parts, tools, or skilled technicians, can affect the repair time. If the required resources are readily accessible, the repair can be completed more quickly.
- The effectiveness of maintenance procedures and practices can help identify potential issues early on and reduce the time needed for repairs.
- The expertise, skill level, and experience of the repair personnel directly impact the MTTR. Experienced technicians who are familiar with the equipment and have troubleshooting capabilities can expedite the repair process.
- Access to comprehensive documentation, repair manuals, and a well-maintained knowledge base can facilitate quicker repairs. Clear instructions and past repair history can assist technicians in diagnosing and resolving issues more efficiently.
Challenges in capturing MTTR
There are a few challenges in capturing MTTR, like:
- Incomplete data. It can be difficult to capture all of the data necessary to calculate MTTR. This is because not all failures are reported, and the reported data may not be accurate or complete.
- Variability. MTTR can vary depending on a number of factors, such as the type of equipment, the severity of the failure, and the availability of replacement parts. This can make it difficult to track MTTR over time and compare it to other organizations.
- Complexity. In some cases, it may be necessary to track MTTR at a very granular level. This can be difficult and time-consuming, especially for large organizations with complex IT infrastructures.
- Cost. Capturing MTTR can require the use of specialized software and hardware. This can be a significant cost, especially for small businesses.
Despite these challenges, it is important to capture MTTR to improve IT performance. By tracking MTTR, organizations can identify areas where they can improve their repair processes and reduce the amount of time that systems are down.
Here are some tips for capturing MTTR:
- Use a standardized process. So, ensuring that all data is collected consistently will be easier.
- Use a reliable data source. This could be a ticketing system, an asset management system, or a dedicated MTTR tracking tool.
- Track all failures. Even minor failures should be tracked, as they can add up over time.
- Use automated tools. This can help to reduce the amount of manual data entry required.
- Regularly review MTTR data. As a result, you will be able to identify trends and areas for improvement.
By following these tips, organizations can capture MTTR more accurately and efficiently. This will help them to improve IT performance and reduce the impact of IT failures.
Examples illustrating the application of MTTR
There are many examples of how MTTR can be applied. Here are a few:
- A manufacturing plant uses MTTR to track the time it takes to repair a broken machine. By tracking MTTR, the plant can identify machines that are more likely to break down and take steps to prevent future breakdowns.
- A call center uses MTTR to track the time it takes to resolve a customer issue. By tracking MTTR, the call center can identify areas where it can improve its customer service and reduce the amount of time customers spend on hold.
- A hospital uses MTTR to track the time it takes to fix a piece of medical equipment that breaks down. By tracking MTTR, the hospital can identify equipment that is more likely to break down and take steps to prevent future breakdowns.
- A school uses MTTR to track the time it takes to fix a broken computer. By tracking MTTR, the school can identify computers that are more likely to break down and take steps to prevent future breakdowns.
- A transportation company uses MTTR to track the time it takes to repair a broken vehicle. By tracking MTTR, the company can identify vehicles that are more likely to break down and take steps to prevent future breakdowns.
These are just a few examples of how MTTR can be applied. By tracking MTTR, organizations can identify areas where they can improve their reliability and performance.
Here are some additional tips for using MTTR:
Use MTTR to set goals. For example, a manufacturing plant may set a goal of reducing MTTR by 10% in the next year.
Use MTTR to benchmark performance. This can help organizations to identify areas where they can improve their performance.
Use MTTR to identify trends. This can help organizations to identify areas where they can take preventive measures.
Use MTTR to make decisions. For example, a hospital may decide to replace a piece of medical equipment if the MTTR is too high.
By following these tips, organizations can use MTTR to improve their reliability and performance.
Delving into the mean time to acknowledge
Mean time to acknowledge, or MTTA, is primarily associated with support or helpdesk functions, quantifying the speed at which a response is provided to users or customers.
The role of MTTA is to assess the timeliness and efficiency of the initial response process. It helps organizations evaluate their ability to acknowledge incidents or requests promptly and set expectations for users regarding response times. Monitoring and improving MTTA can lead to enhanced customer satisfaction, improved service levels, and efficient incident management.
How to calculate MTTA?
Discover the power of MTTA calculation in optimizing your incident response. Simply sum up the time elapsed between alert and acknowledgment for each incident, and then divide it by the total number of incidents.
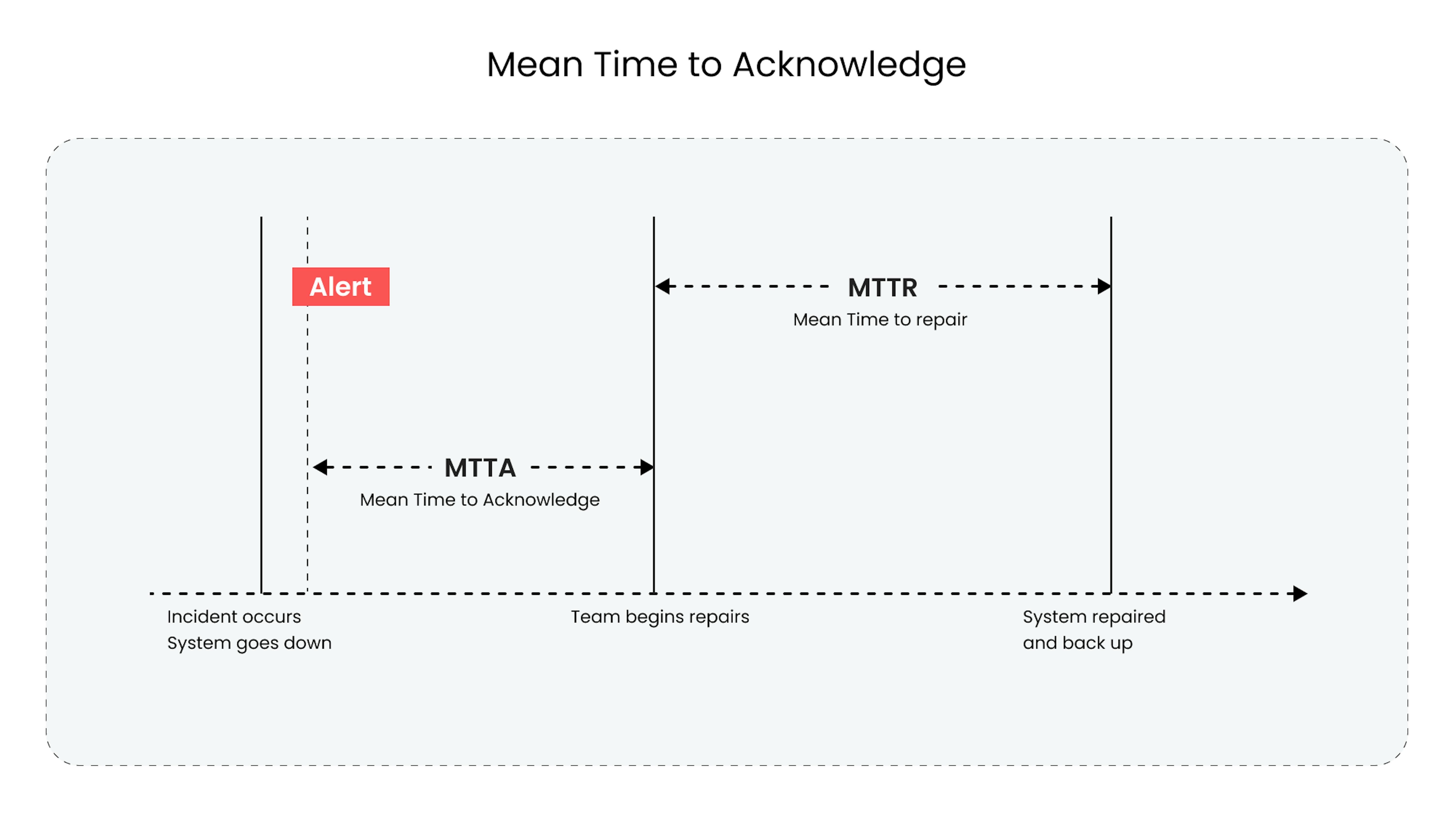
Picture a scenario where a system experiences consecutive events: the first one takes 3 minutes for the team to notice, while the second event requires 7 minutes for acknowledgment. In this case, the team's MTTA shines at an impressive 5 minutes. Unleash the power of this metric to fine-tune your response strategies and ensure swift incident resolutions that keep your systems thriving.
What factors influence MTTA?
Here are three factors that can influence MTTA:
- Team responsiveness. The speed at which the team acknowledges alerts or incidents is crucial in determining MTTA. Factors such as team size, availability, and communication channels can impact how quickly the team can respond to and acknowledge incidents.
- Workflow and automation. Efficient workflow processes and automation tools can significantly reduce MTTA. Streamlining incident management processes, implementing automated alert systems, and utilizing notification tools can help expedite recognition.
- Training and skill level. The knowledge and skills of the team members directly affect MTTA. Well-trained team members who possess a deep understanding of the system, incident management protocols, and effective communication techniques are more likely to respond promptly and acknowledge incidents promptly.
Organizations can reduce MTTA and improve incident response times by addressing these factors and optimizing team responsiveness, workflow efficiency, and skill development.
Challenges in capturing MTTA
Unveiling the complexities of capturing MTTA, we encounter various challenges that demand attention.
- Firstly, the accurate recording and synchronization of incident alerts and responses is challenging, requiring robust monitoring systems and streamlined processes.
- Secondly, the presence of multiple communication channels and platforms adds intricacy, as consolidating data from disparate sources becomes a priority.
- Additionally, human factors such as delays in response or varying levels of expertise contribute to the challenge.
Overcoming these obstacles necessitates diligent data management, clear communication protocols, and continuous refinement of incident response practices. By addressing these challenges head-on, organizations can enhance their MTTA measurements and ultimately improve their overall incident management capabilities.
Examples illustrating the application of MTTA
MTTA can be applied in various contexts where incident management and response time are critical.
- Customer support. MTTA plays a crucial role in customer support operations. It measures the time taken to acknowledge customer inquiries, requests, or reported issues. Prompt acknowledgment is vital for maintaining customer satisfaction and delivering timely assistance.
- Security incident response. MTTA is relevant in security operations to acknowledge and respond to security incidents, such as breaches or cyber-attacks. Recognizing the issue quickly allows for rapid containment and investigation, helping minimize the potential impact and ensure data protection.
- Emergency response. In emergency management scenarios, MTTA is crucial for acknowledging critical incidents, such as natural disasters, accidents, or security threats. Providing timely acknowledgment ensures effective coordination among response teams and facilitates prompt actions to mitigate risks.
Overall, MTTA can be applied in any situation where acknowledging incidents or requests promptly is essential for maintaining service quality, resolving issues efficiently, and meeting customer expectations.
Unveiling mean time to failure
Mean time to failure, or MTTF, measures the amount of time that passes between non-repairable failures.
How to calculate MTTF?
MTTF= total number of operational hours / total number of assets in use
To calculate MTTF, divide the total number of hours of operation by the total number of assets in use.
- MTTF = Total hours of operation ÷ Total assets in use
- MTTF = 10,000 hours ÷ 40 assets
- MTTF = 250 hours
Since MTTF indicates the average time to failure, calculating it with more assets will yield a more accurate result. Suppose you wish to compute the MTTF of your facility's conveyor belt rollers. 125 identical rollers have completed 60,000 hours of service in the last year. This is how your MTTF calculation might look:
- MTTF = Total hours of operation ÷ Total assets in use
- MTTF = 60,000 hours ÷ 125 assets
- MTTF = 480 hours
You can estimate that a roller's average life expectancy at your facility is 480 hours.
What factors influence MTTF?
Here are several factors that can influence MTTF:
- Design and manufacturing quality. The quality of the product's design and manufacturing processes can significantly impact its reliability and, consequently, its MTTF. Products that are designed and manufactured to high standards are likely to have longer MTTF values compared to those with design or manufacturing flaws.
- Component reliability. The reliability of individual components used in the product plays a crucial role in determining the overall MTTF. Components with higher reliability, such as high-quality electronic components or durable mechanical parts, contribute to a longer MTTF.
- Usage patterns. How the product is used and the intensity of its usage can impact its MTTF. Products subjected to heavy or continuous usage may experience higher stress levels, potentially leading to shorter MTTF values. On the other hand, products used sporadically or under controlled conditions may have longer MTTF values.
- Maintenance practices. The quality and frequency of maintenance performed on the product can influence its MTTF. Regular maintenance, including inspections, cleaning, and preventive repairs, can help identify and address potential issues before they lead to failures, thereby increasing the MTTF. Inadequate or irregular maintenance practices may result in shorter MTTF values.
- Product aging. Over time, the aging of materials and components can lead to degradation and increase the likelihood of failures. MTTF values may decrease as a product ages due to wear and tear, material deterioration, or the accumulation of usage-related stresses.
Challenges in capturing MTTF
Capturing MTTF can present certain challenges due to the following factors:
- Limited sample size. Obtaining a sufficient number of failure data points can be challenging, especially for products or systems with long lifespans. Limited sample size may lead to less accurate MTTF calculations and potentially overlook certain failure patterns or trends.
- External factors. MTTF calculations can be influenced by external factors such as environmental conditions, usage patterns, or maintenance practices. Capturing and accounting for these factors accurately can be complex and may require extensive data collection and analysis.
- Repair and replacement data. Obtaining accurate and complete repair and replacement data is crucial for calculating MTTF. However, in some cases, such data may not be readily available or may not be consistently recorded, making it difficult to capture the true failure rates and calculate reliable MTTF values.
- Predictive modeling. Predicting future failure rates and estimating MTTF for new or evolving technologies can be challenging due to the lack of historical data. In such cases, predictive modeling techniques and assumptions may need to be applied, introducing additional uncertainties.
Examples illustrating the application of MTTF
- Electronic devices. In the electronics industry, MTTF estimates the reliability of devices such as smartphones, laptops, or televisions. It helps manufacturers determine the average lifespan of their products and make design improvements to enhance reliability.
- Automotive industry. MTTF is utilized in the automotive sector to assess the reliability of vehicle components, such as engines, transmissions, or braking systems. By analyzing the MTTF, manufacturers can identify potential weak points and improve the overall durability and performance of their vehicles.
- Industrial equipment. MTTF is relevant for machinery and equipment used in industrial settings, such as manufacturing plants or power generation facilities. It helps determine the average time until a failure occurs in critical components, allowing for proactive maintenance planning and minimizing unplanned downtime.
Choosing the right metrics and improving performance
To effectively measure and improve the reliability and performance of your systems, it is crucial to choose the right metrics and implement strategies for continuous improvement.
Set realistic targets for each metric based on industry standards, best practices, and your organization's specific requirements. Consider factors such as customer expectations, operational goals, and the criticality of systems.
Monitor the metrics regularly to assess performance against the targets. Identify areas where improvements can be made and prioritize them accordingly. Here are some continuous improvement strategies:
- Conduct root cause analysis. Investigate the underlying causes of failures and incidents to identify patterns and recurring issues. Addressing root causes helps prevent future failures and enhances system reliability.
- Implement preventive maintenance. Regularly schedule maintenance activities, inspections, and system updates to identify and fix potential issues before they lead to failures.
- Invest in training and resources. Ensure your team has the necessary skills, knowledge, and tools to manage and troubleshoot systems effectively. Continuous training and keeping up with technological advancements are essential.
- Foster a culture of improvement. Encourage collaboration, knowledge sharing, and open communication within your organization. Empower your team to propose ideas and implement innovative solutions for enhancing reliability.
By choosing the right metrics, setting performance targets, and implementing continuous improvement strategies, you can optimize the reliability and performance of your systems, minimize downtime, and deliver a seamless experience to your users.
Remember, these metrics should be used in conjunction with other relevant indicators and tailored to your specific business needs to provide a comprehensive assessment of system performance.

Conclusion
In conclusion, understanding and effectively utilizing metrics such as MTBF, MTTR, MTTA, and MTTF are essential for evaluating the reliability and performance of systems and equipment. These metrics provide valuable insights into the frequency of failures, the speed of recovery, and the overall availability of critical assets.
By implementing strategies to improve these metrics, organizations can enhance their operational efficiency, minimize downtime, and optimize resource allocation. This includes proactive maintenance practices, investing in high-quality components, optimizing repair processes, and continuously monitoring and analyzing data to identify areas for improvement.
It is crucial to consider the unique characteristics of each metric and their respective roles in measuring reliability and system performance. Additionally, factors such as data accuracy, standardization, and capturing challenges should be addressed to ensure the validity and reliability of the metrics.
By applying the knowledge and best practices outlined in this guide, organizations can make informed decisions, enhance system reliability, and ultimately drive business success through improved uptime, customer satisfaction, and cost efficiency. Understanding and leveraging these metrics will empower businesses to optimize their operations, maintain a competitive edge, and deliver reliable and resilient solutions in today's technology-driven landscape.


FAQ
What is the difference between MTBF and MTTR?
How are MTBF, MTTR, MTTF, and MTTA used?
What are the typical values for MTBF, MTTR, MTTF, and MTTA?
Latest articles here





