


More and more companies are looking for ways to save money on a project. Modern companies face various costs when developing a product, prompting them to control costs and finances effectively. This means finding ways to save money so the project runs smoothly after release. Companies can save a significant amount for the business by looking for the best options.
Recently, this happened with a project that the Mad Devs team was working on. We have been working on optimizing the cost of cloud computing for a PaaS project. Today we will figure out how we saved $10,000 per month on the Google Cloud Platform, what we did for this, and why we had to spend $2,000 in one day. By reading this article, you will gain insights into the following:
- About the project
- Identifying problems
- Preparing a list of resources for optimization
- Work plan and archiving work
- Have we managed to save money?
Join us as we delve into the world of cost optimization on the Google Cloud Platform and discover practical tips to reduce expenses while navigating potential challenges.

About the project
The Mad Devs team is working with an American startup developing a cloud-based product that allows doctors to determine the type and degree of mental health issues that person has by voice recording. Colleagues from the startup say the following about the product:
This voice biomarker technology uses the power of artificial intelligence and voice to detect signs of depression and anxiety. Our product fits existing clinical workflows with an API-first platform and helps clinicians in real-time.
In general, this describes the system being developed accurately. Our team is involved in developing all parts of this product except for machine learning (ML). The startup has its own full-time ML engineers and biologists team for this purpose.
Identifying problems
Briefly about the infrastructure of the project: it is built on two pillars—Google Cloud Platform (GCP) and GitLab. The team does not use any third-party systems other than Vanta compliance for internal reasons.
In the optimization, the first task was to refactor the core Terraform product code to deploy dev, staging, and prod environments in separate projects and migrate to new environments. IaC was not functional in the project at that time due to significant discrepancies between the Terraform code and the current state, which was managed manually. IaC is a technique where code manages infrastructure, including applications and programs. In this case, the infrastructure changes were made manually without corresponding changes in the Terraform code. If we ran this code, all manual changes would be overwritten, and we would lose our infrastructure. To solve this problem, we redesigned the code and deployed a separate new infrastructure, to which we then transferred our project and removed the old infrastructure.
During the refactoring of the infrastructure, various accesses to GCP were obtained step-by-step, including access to billing. From our side, the billing was studied especially carefully to assess the cost of infrastructure after refactoring and an attempt to reduce old/unnecessary services.
We have put together a cost estimate plan:
- Download the report from billing and analyze it, paying attention to significant expenses.
- List unnecessary/unused/costly services and ask the team about opportunities to cut costs.
- Based on the feedback, form a plan to reduce costs.
Preparing a list of resources for optimization
After an initial review of the billing report, it turned out that there are about 30 projects in the GCP in an inexplicable state, some of which spend a substantial amount of money per month.
What we found out:
The main product project had three environments, dev/staging/prod, so that the infrastructure cost can be multiplied by three.
In dev/staging, the Cloud IDS service was deployed to pass SOC 2 and HIPAA compliance, but it is only used in prod. (Approximately $2,300–$3,000 per project per month, depending on the amount of tests, for a total of $4,600–$6,000 per month.)
The Shared Infra project spent more than $8,000 per month on maintaining unusable discs.
Two older versions of the product cost $2,600 per month and were no longer in use.
Work plan and archiving work
Based on the available information, an optimization plan was developed, and the following tasks were completed:
- CloudIDS was disabled in the dev/staging environment using the 'env_prod' flag in Terraform.
- Old projects were deleted after archiving sensitive data.
- Old, unused disks were archived and deleted. We will discuss this in more detail below.
We calculated the cost of the disk using the following formula:
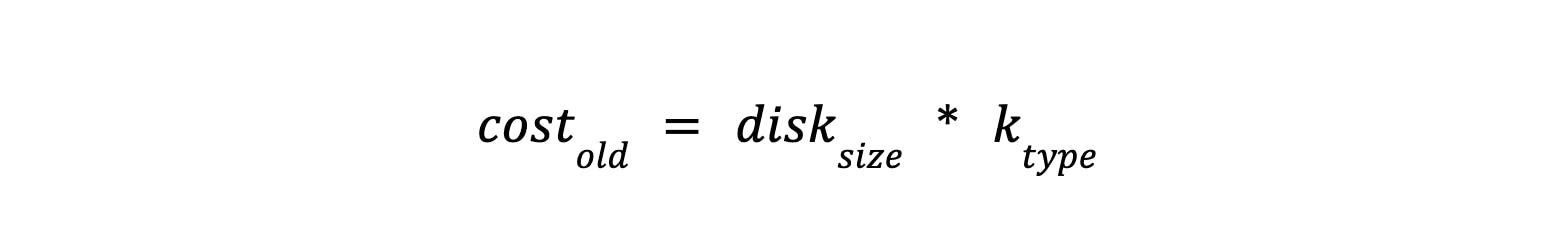
Where disk size is the size of the disk and k type is the ratio of the cost per disk per month based on the type.
The project mainly used Balanced PDs with k type = 0.1 GB per month, with an average size of 2 TB. The cost of using one disk was $200 per month. It is important to remember that the disks did not use all available storage. That when archiving also helped save money.
One of the most cost-effective options for storing a large amount of data has become for us Google Cloud Storage. By choosing the Coldline storage type, we have achieved that our k type per GB has become 0.004, which is 25 times less than the previous one and helps save a significant amount of money.
We wrote a bash script based on gsutil tool to copy data to Google Cloud Storage buckets.
If you want to speed up the copying process, use the -m flag, for example, gsutil -m cp ./local_folder gs://bucket_name/. This will significantly accelerate the data copying process.
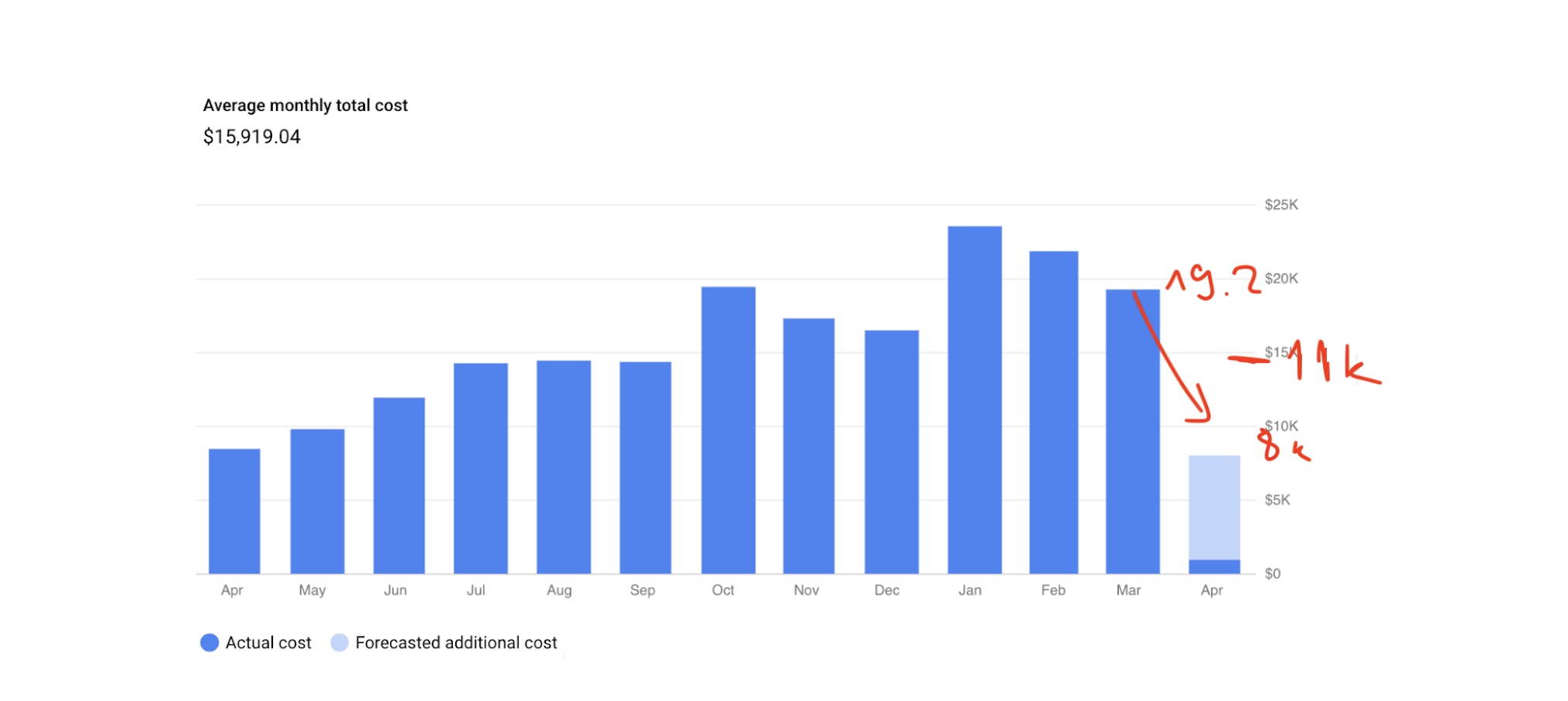
As a result, after the data transfer and disk deletion, it was planned to save $11,000.
This is how it should have looked like:
Have we managed to save money?
Unfortunately, our cost savings were not as significant as we had hoped. In April, we were approached by new colleagues from the ML Team, who urgently needed 2 virtual machines with 4 Nvidia Tesla A100 40G each. Each GPU in them costs $2,141, so 1 virtual machine started to cost us $9,000 per month.
A total of $18,000 per month for two virtual machines. Unfortunately, colleagues from the ML team created these virtual machines without informing us, which ruined our plans and calculations.
Subsequently, we discussed all this with the team, and the colleagues lowered their expectations. However, because of these incidents, we even spent a little more than the previous month, despite saving a lot on disks.
If you look at the graph at first glance, it may seem that we did not save at all:
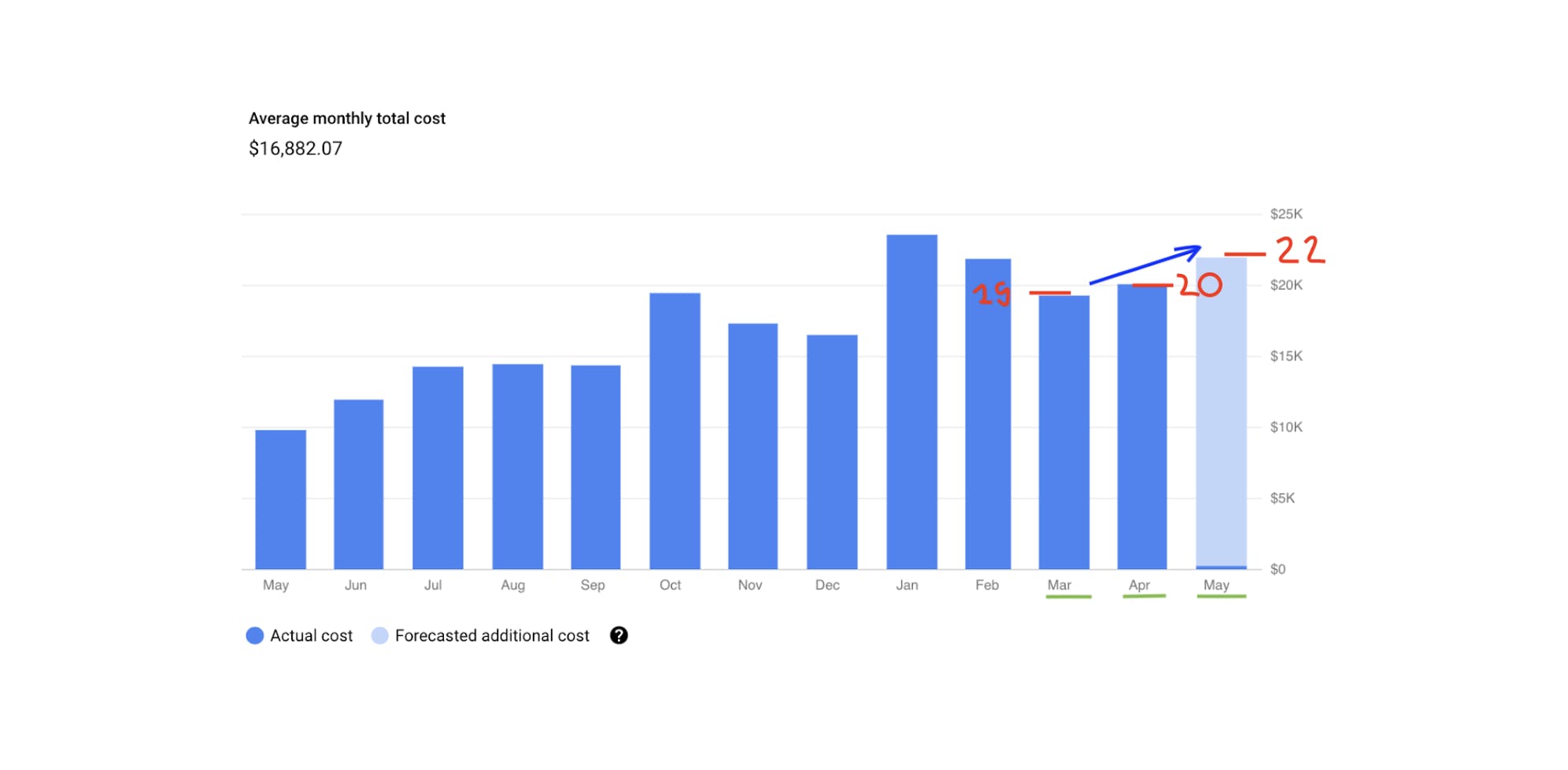
According to preliminary estimates (taking that no one makes anything new), we will spend about $22,000. Considering that we were deleting old/archival disks, ML Team engineers would deploy their virtual machines for $8,000-10,000 per month anyway, and then we would come to a cost of about $30,000-35,000 per month.
Final thoughts
What conclusions can be drawn? A few things come up at once:
- Try to do regular internal infrastructure audits and keep track of costs.
- Control the process of introducing new features and assess their cost before implementation.
- Ask questions more often, such as "Do we need this? Do we understand exactly how we will use it?".
- Cutting costs is an ongoing struggle, but trying to relax and have fun along the way is essential.

Latest articles here





